
Let's get one thing straight up front: there are tools that watch your cloud, and there are tools that run it. Almost everything sold as "observability" is the former. AlertD is the latter.
That distinction matters. Operations teams have been swimming in observability for years. And the dirty little secret is "mo' signals, mo' problems." Put bluntly, observability floods you in signal — metrics, logs, traces — but fails on the hard part: sifting signal from noise and providing actionable insights. That part's dropped in your lap. You build the dashboards. You write the queries. You hand-tune the alerting rules. And then you drown in it, as your fleet changes underneath you.
We think that's backwards. So we built the opposite. We think The System has to observe and comprehend the flood of signals. AlertD does exactly that, and we do it with zero configuration. You heard right.

Fully AI-native means:
- You will never install a "collector."
- You will never build a dashboard.
- You will never write a query.
- You will never waste time writing alerting rules that are garbage within 24 hours — stale the moment someone resizes an instance, ships a new service, or doubles the traffic.
AlertD isn't a replacement for observability. It's something entirely different. It's a platform for cloud operations that helps you wrangle infrastructure at scale: Cost, Compliance, Security, and Performance.
If you're drowning in your own signals, you can't make use of them. So AlertD started from the ground up with foundational fleet-scale observability and a friendly agent named Flappy, who sees it all.
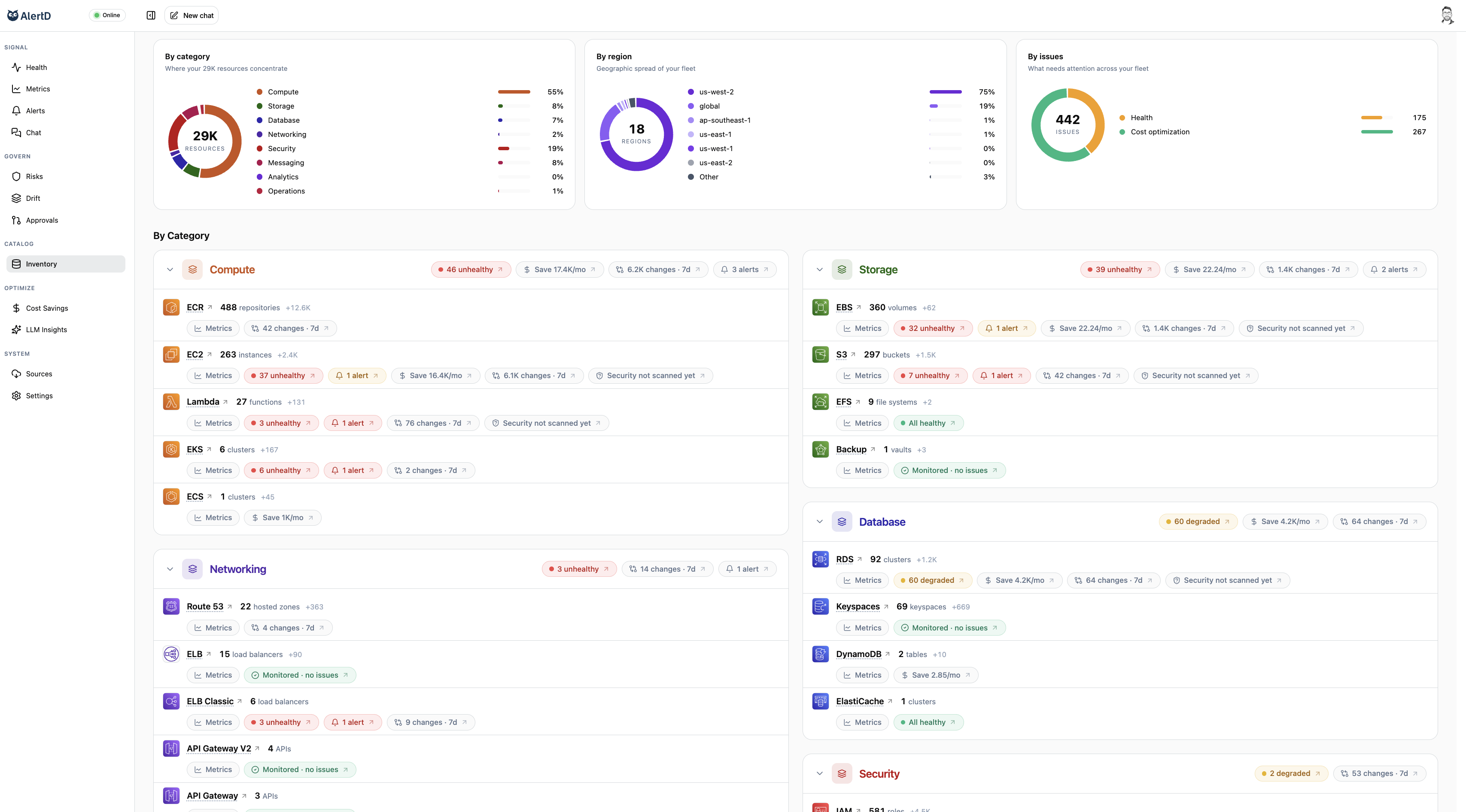
It starts with inventory

AlertD's datacube sees everything you have. Every QA environment, every sales guy's old demo, every forgotten RDS database, every backwater of storage. Everything. Automatically. Zero configuration. Within an hour of installing AlertD, it's auto-inventoried your cloud — across regions, and across accounts. When we say everything, we mean everything.
Then we link inventory to metrics

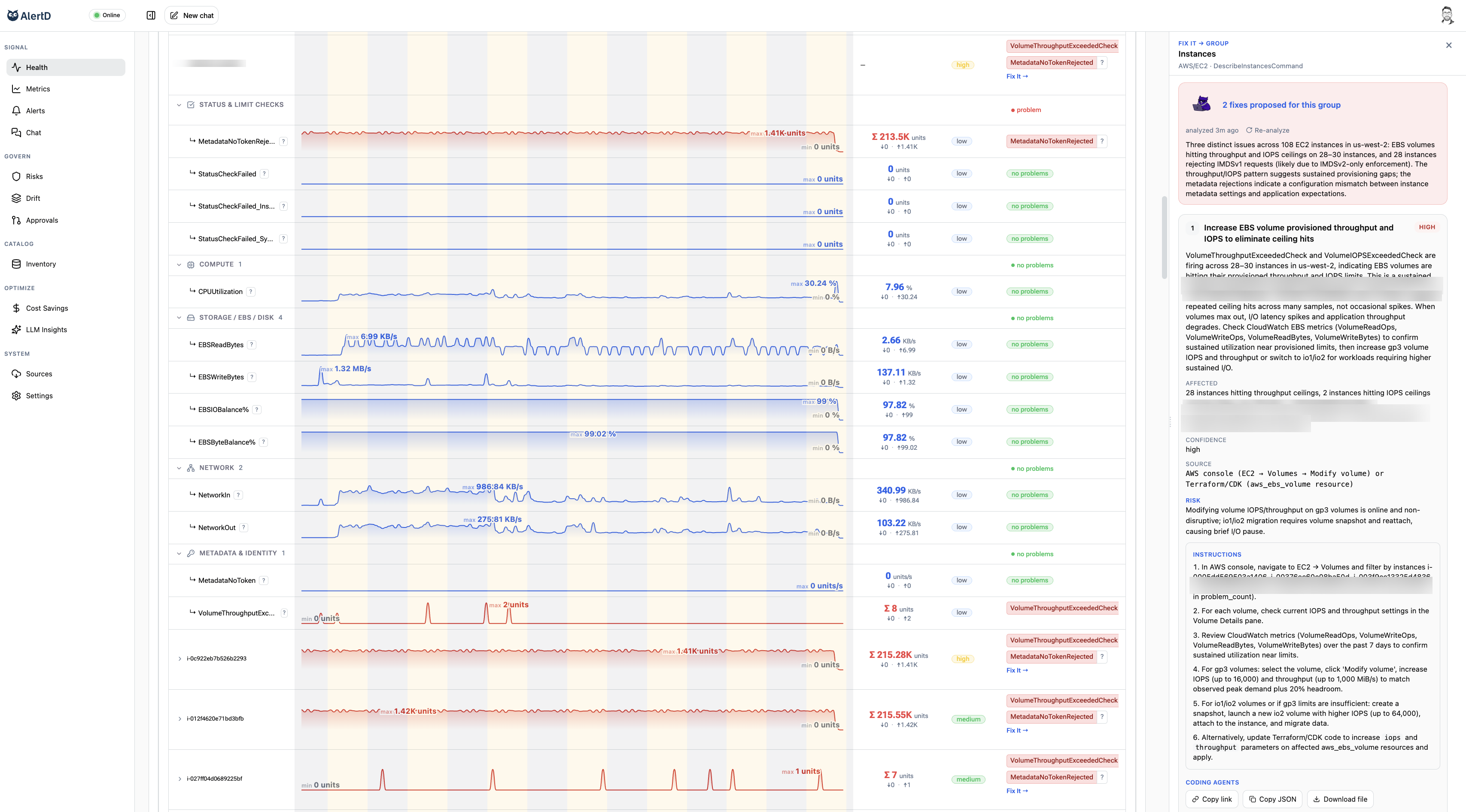
AlertD ingests every metric, for every resource, without a single configuration file. How is this possible? Surprise: AI. AlertD quickly learns exactly what metrics exist, and which metrics are most valuable. Automatically. Zero human touch. Never write a Grafana dashboard again. Flappy is continuously monitoring the right combinations of signals so that when problems brew, you'll find out before they get hot.
Then we map your topology

AlertD autonomously finds the key relationships between all resources and metrics, building a continuously updated map of your infrastructure topology. Now we know how every resource relates to every other resource — how a change to A impacts B, and how B impacts C. You can see and navigate it on screen, but why bother? Flappy understands it so you can focus on what matters most.
New features, lunch, or maybe leaving work by 5:00.
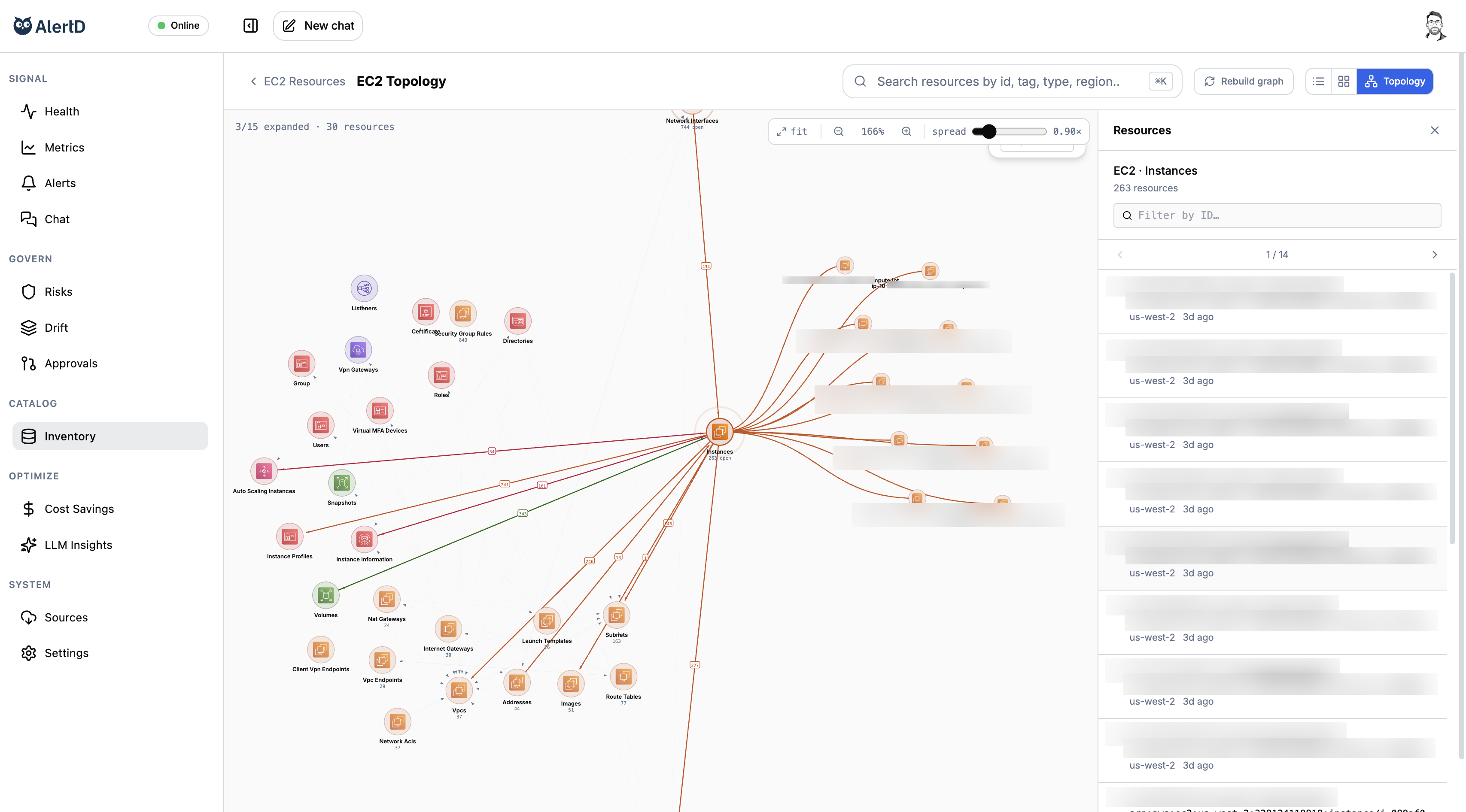
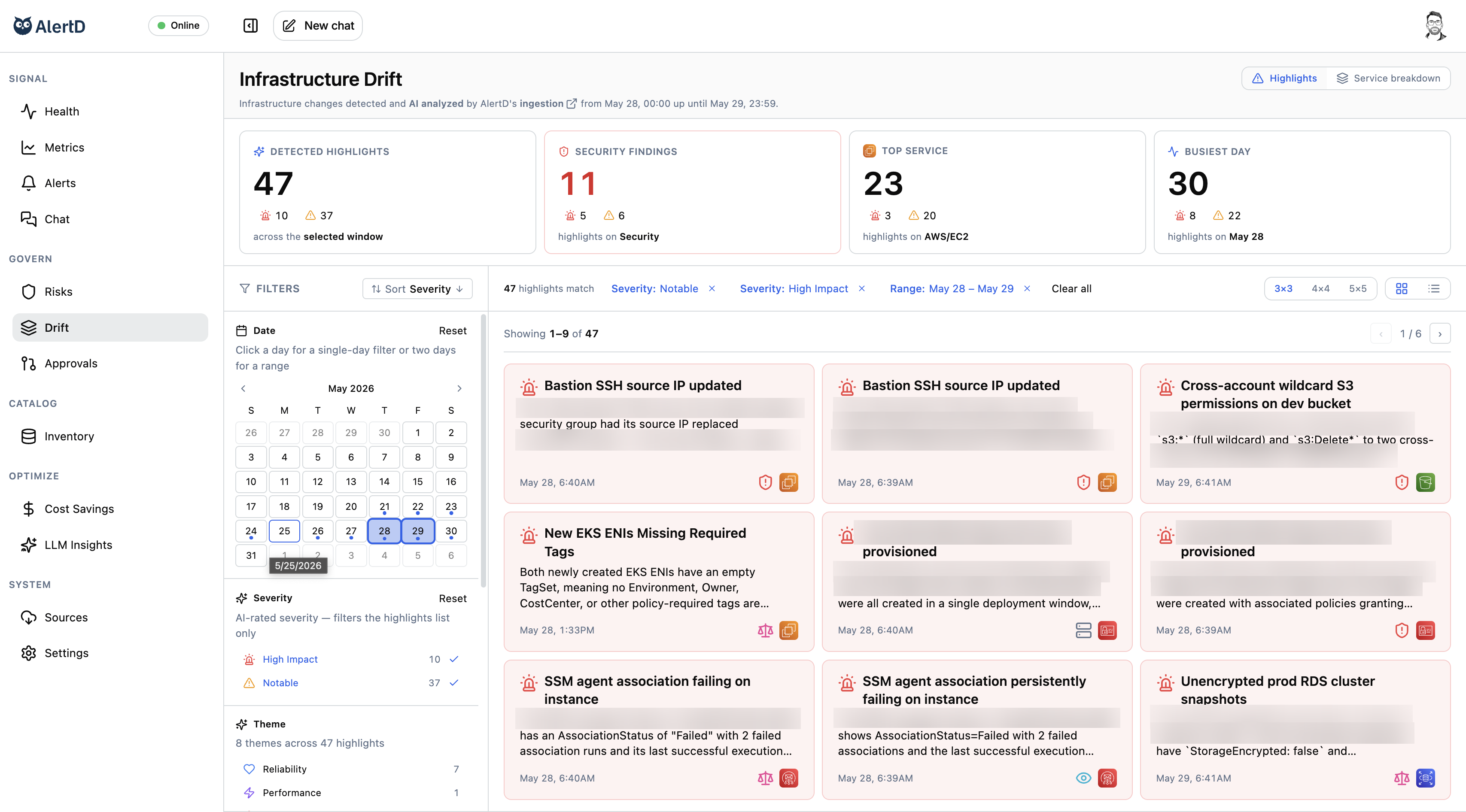
Oh yeah, and whenever anything changes, we pick that up too. Drift? Orphaned resources? Not any more. AlertD watches every change, and understands them as they happen. That's how we catch every rogue CLI command, and every "hot fix" your team swears they'll commit to IaC "real soon."

AlertD never forgets, it never gets distracted, and it never asks for help. Want to see for yourself? Check it out in infra-diff mode. Don't GAF? Flappy's got this. Hands free, with a bluetooth earpiece the size of a kazoo.
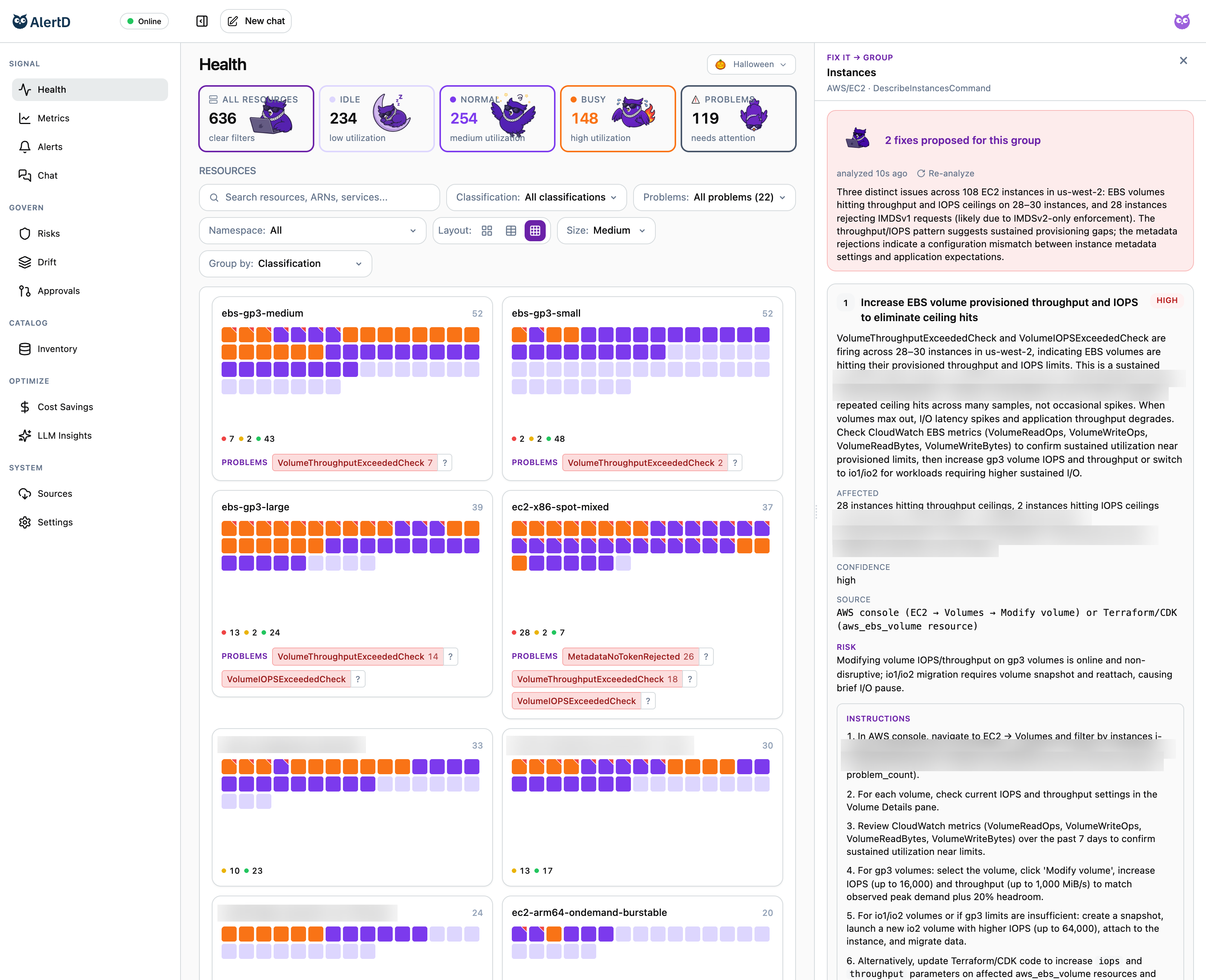
Auto-classification, or "What have we really got here?"

Here's the reality: most cloud ops teams lose track of what's what. The wasted spend tells the story. Because "what we have" and "what it's for" are two very different beasts. The challenge of auto-classification hasn't been solvable — until AlertD came along and choke slammed it like Cactus Jack. Surprise: automatic clustering, classification, and cohort building. We have the screens. All of which we hope you never look at. No offense.
ℹ️ Ooo, wait one second… are your tags a total mess?
Gotcha! We don't need your tags. If you've got 'em, flaunt 'em. If you don't — well, then your infra's just as crappy as everyone else's. Flappy will fix your tags.
Monitor everything — alert on what matters
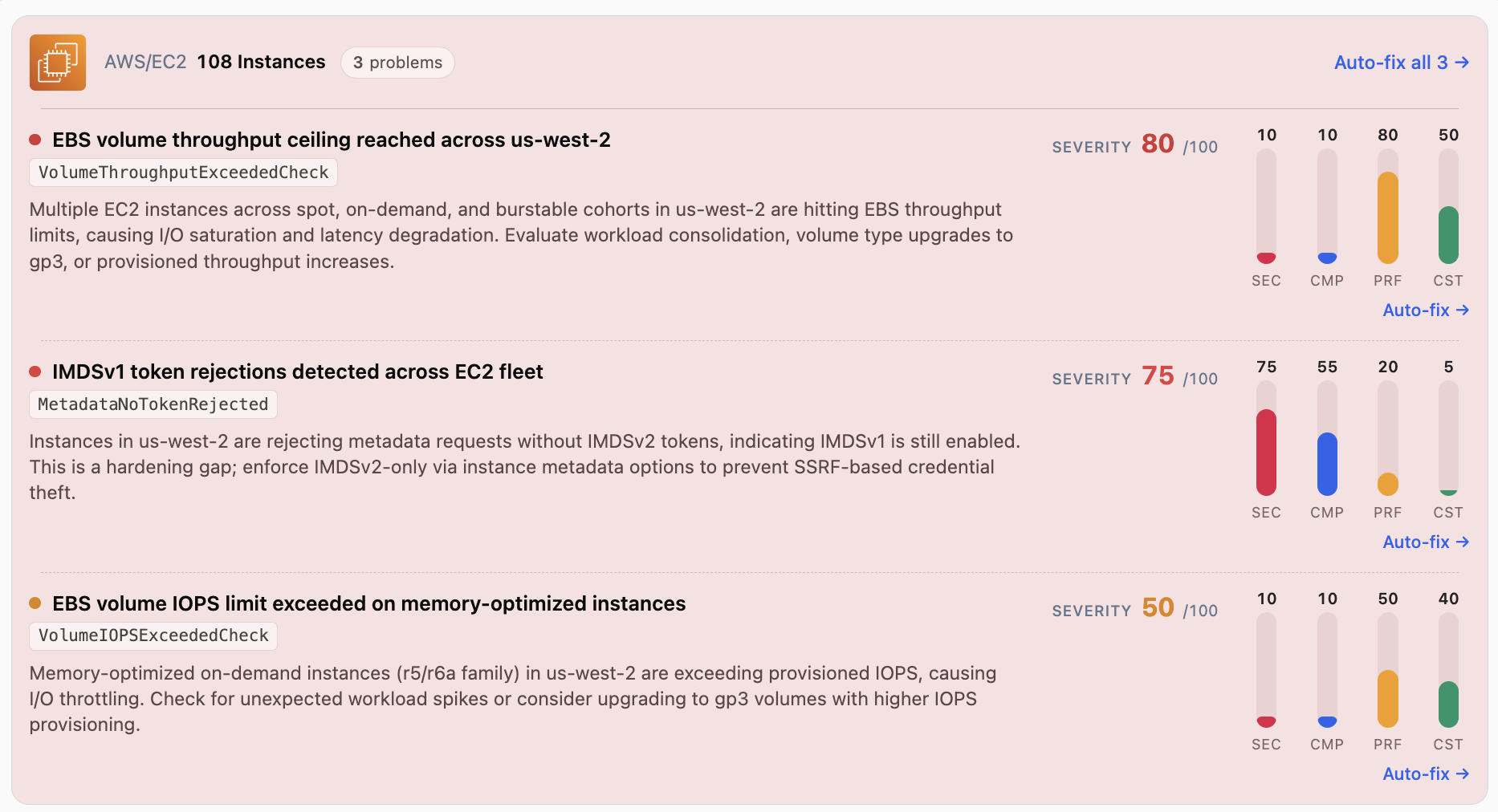
The industry's answer has been: write more rules. A rule per service, per environment, per instance class. Which is exactly the treadmill that kills productivity — by the time you've tuned your rules, the fleet has moved, and half your rules now page on noise or stay silent on real failures. Your ops team becomes alert monkeys; never the right rules, never the right dashboards.
AlertD's answer is different: don't write thresholds at all. Don't write rules. Let AlertD derive everything.

Remember "AIOps"? That thing where they were gonna "use ML to look at all the metrics"? That thing that never worked? Yeah, that thing. We just made it work. When you use AI to link every metric to every resource, and you understand the semantic meaning of every resource and its usage over windows as long as 30 days, then suddenly your alerts work and make sense. Context is the key, and Flappy has all of it. Here's the even better news: it's not possible for a human to "configure" these kinds of alerts. AlertD takes a pure AI-native, zero-configuration approach.
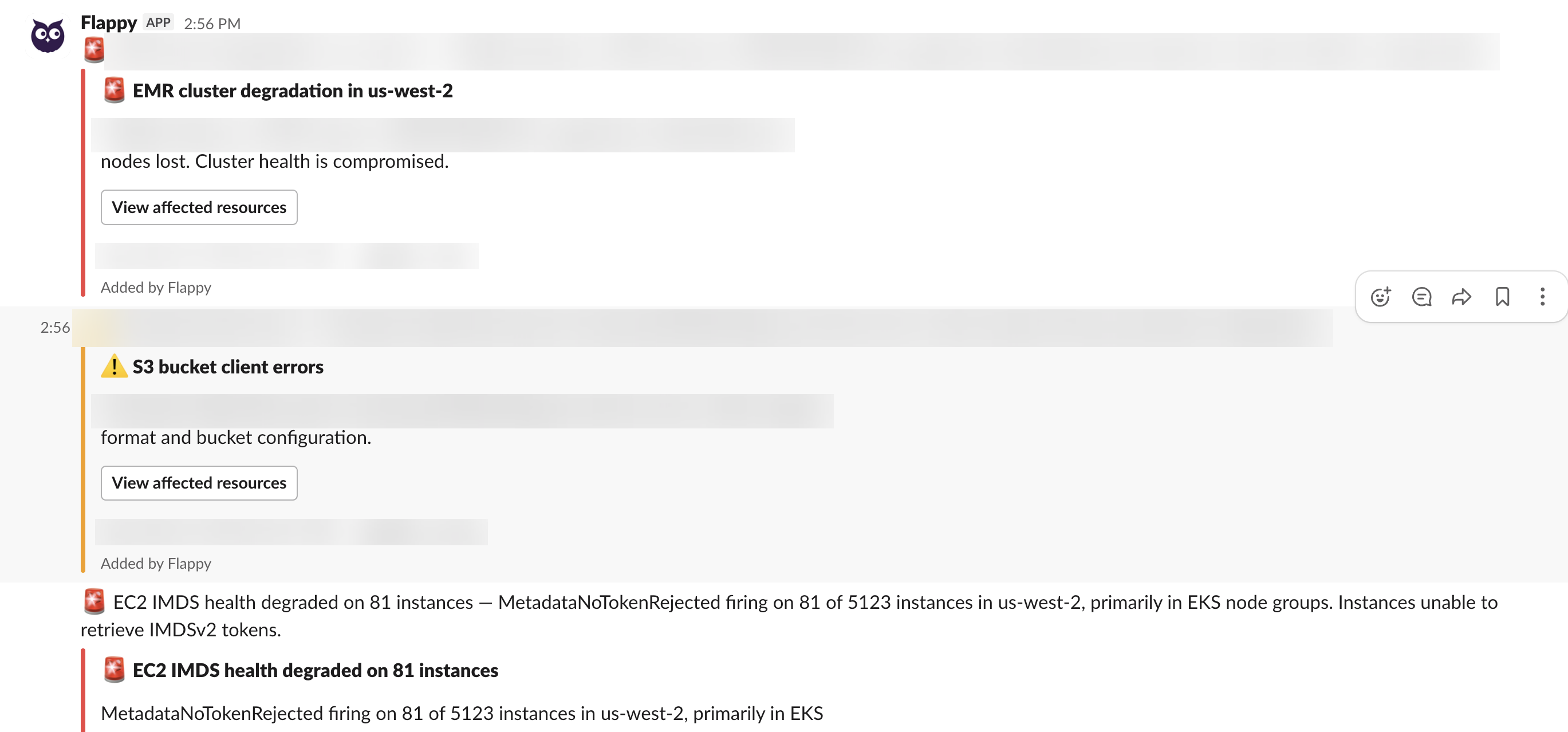
AlertD comes to where you work
Nobody wants to learn another tool or platform, and the good news is AlertD is a zero-learning experience. Most of the interaction with AlertD is initiated by Flappy on Slack. Unlike other Slack alerting solutions, Flappy is a fully conversational agent that has access to the entire system state.
The bottom line

Observability tools give you instruments and a manual, and then siphon off 1/3 of your cloud budget to throw noise back at you. AlertD gives you operations: it discovers your fleet, decides what "normal" means for every cohort it learns, grades health against that baseline continuously, and shows you the result — without a single dashboard, query, or alerting rule. But that's merely the appetizer.
The main course is what we serve on top of observability: immediate optimization across 4 dimensions.
COST — If you spend $1M annually on AWS, you can expect AlertD to slash your AWS bill by $100K this year.
SECURITY — Flip AlertD on, and within minutes Flappy will find and help you fix dozens, if not hundreds, of critical security gaps.
COMPLIANCE — If you've got a broken or half-baked compliance posture, Flappy will get you ship-shape quickly — analyzing your deployments, and implementing and enforcing comprehensive tagging.
PERFORMANCE — Rightsize complex EKS operations, optimize for ECS, and squeeze the most out of GPUs. Do more with less!

