
If your team is anything like the engineering teams that AlertD works with, you’re going through an exciting, risky, and even scary time as AI becomes central to everything. You’re retooling existing apps with AI, writing new apps with AI that themselves use AI, and achieving velocity you never thought possible. But on the flip side, you’re worried about security risks, out-of-control costs, and losing any form of governance over what the heck your exploding token budget is being consumed by.
To address these concerns, AlertD recently added AI inference optimization to our growing portfolio of cloud optimization and AI automation features. We needed these features ourselves, and we were inspired to dogfood them by a conversation that happened at our daily standup.
The standup that stopped everything

Eduardo has been working on AlertD’s automatic infrastructure change tracking features, and a discussion in standup unfolded something like this:
“Hey Eduardo, how much LLM are you using to implement the classification and alerting we use for infrastructure change tracking? How much do you think it’ll make our customers’ inference bill jump?”
“I’m not really sure. I mean, I know how I’m doing — but I can’t tell you exactly how much that translates into in costs.”
So, right there, we saw exactly what every company is facing. A random new feature might have just caused a 100x increase in your LLM costs. Scary.
That brief conversation caused a “stop everything” moment. We immediately realized we were feeling the same pain that every shop in the industry is feeling. We didn’t want to get burned, and we didn’t want our customers to get burned, by costs that aren’t understood and usage that can’t be categorized and explained. If there was a spiking new cost, we wanted to know immediately.
Why traditional observability doesn’t work for LLMs
The first thing we had to think through was how to get the instrumentation we needed. Unlike traditional REST or in-process method calls, the “meaning” of an LLM call isn’t easily captured by simple parameter values. Age-old observability methods like capturing and enumerating parameter values simply don’t work. The parameter values are huge blocks of free text that defy simple categorization like “date,” “number,” or “integer.”
On AWS, most customers run inference by sending their LLM calls to Bedrock. Bedrock provides a solid foundation, letting different applications set up different inference profiles. But this is essentially traditional instrumentation. It doesn’t give you insight inside the LLM call, and it relies on hygiene — which is in short supply.
This means we need a way to peer inside the payloads to determine what the system prompts and user data actually are, and what they mean. The analogy here is deep packet inspection. To truly get insights into traffic, host/port + source/destination just aren’t enough — hence looking inside the payload.
The purpose of this deep prompt inspection is to cluster and categorize your usage of LLMs. It may sound esoteric, but it’s entirely practical. Take a look at this bar chart and the labels on it. It provides clear evidence for what we use LLMs for, how much it costs, and how those costs rank.
From hearsay to hard data with deep prompt inspection
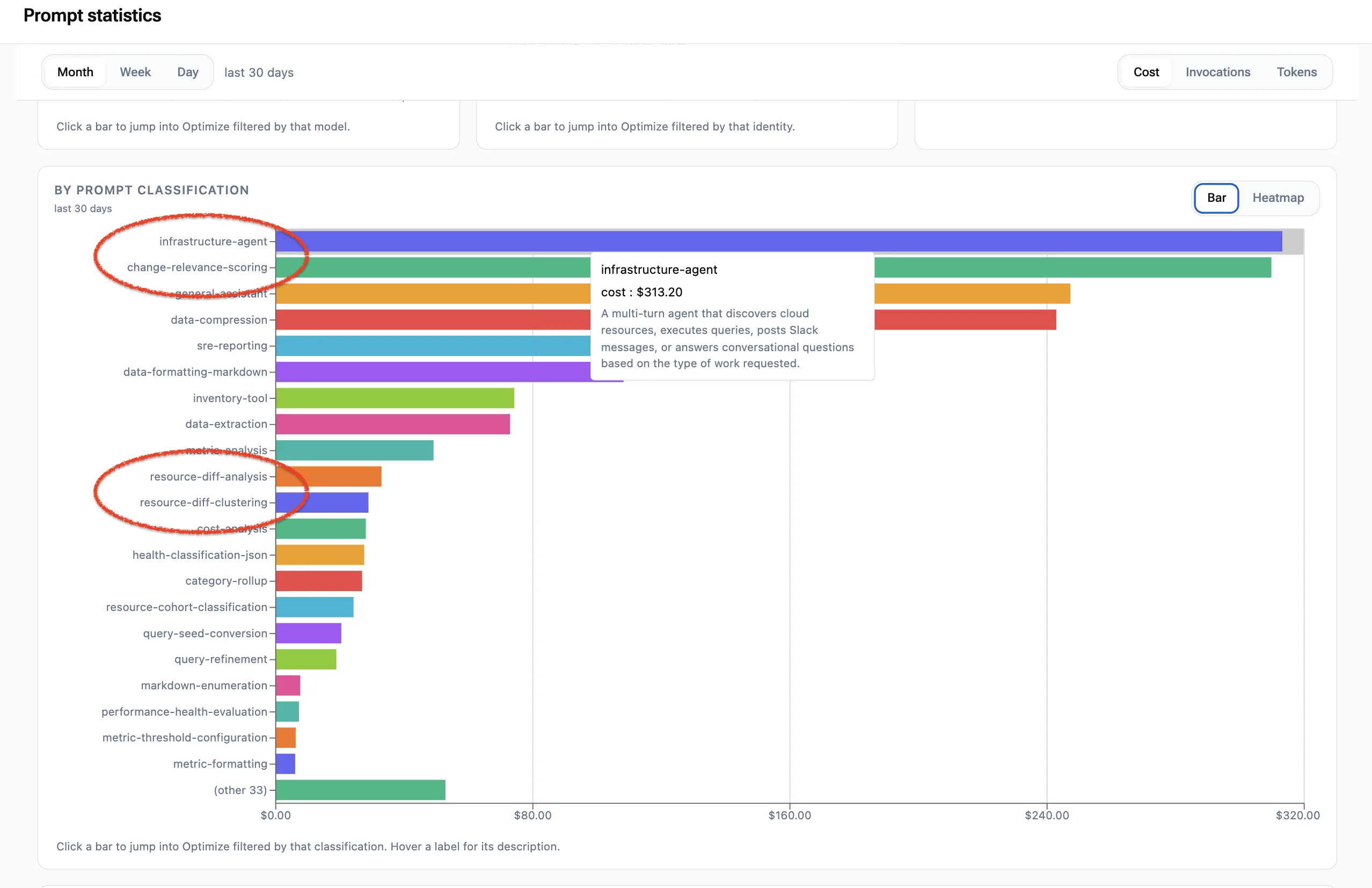
Returning to the conversation at our standup — “Hey Eduardo, how many tokens are you using?” — you can see that this bar chart provides the immediate answer. AlertD has auto-classified, clustered, and grouped the traffic by looking inside the prompts sent by the application.
This bar chart changed the game. Instead of “I’m not really sure how much my new feature uses LLM,” we now saw crystal-clear evidence that four specific prompts had dramatically increased our LLM bill. And from their classification, we could easily see that these four prompts were clearly associated with our new Infrastructure Change Tracking features.
infrastructure-agentchange-relevance-scoringresource-diff-analysisresource-diff-clustering
None of this required Eduardo to go back and retool his code or add any instrumentation. AlertD did it by semantically clustering the contents of the prompts themselves and assigning auto-generated, meaningful names to the clusters. We now had clear evidence and data instead of hearsay and hand-waving. Instead of a nebulous conversation around “not sure exactly what we spend on the new feature,” we now had data clearly identifying it as our largest LLM cost.
You might worry that autoclassifying prompts is itself a massive consumer of LLM. But don’t worry, we autoclassify using ML methods more typically associated with search engine page dedupliction. It’s very light on LLM usage.
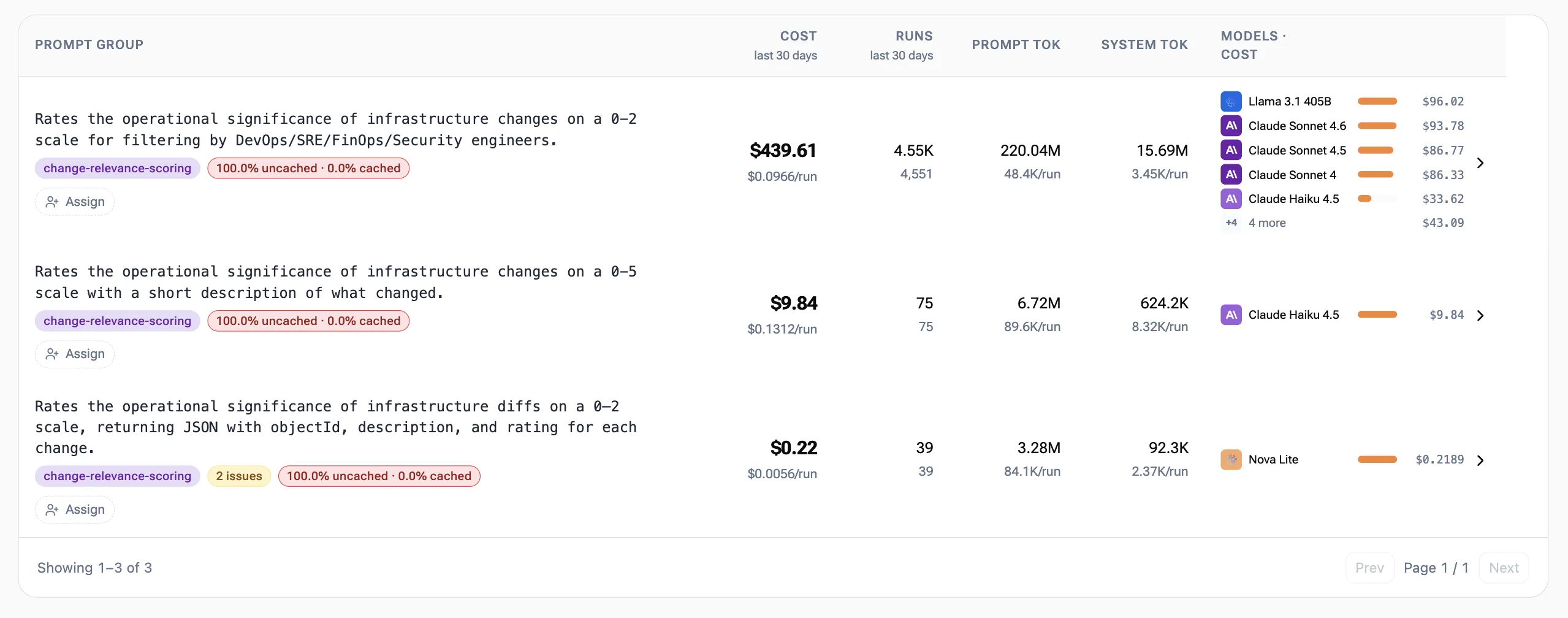
Drilling into a use case
Clicking through on one of the bars — say, change-relevance-scoring — yields the variations of the prompt that are running for that use case. The total cost over the selected time range, the cost per run, and the cost breakdown across the models in use are all included.
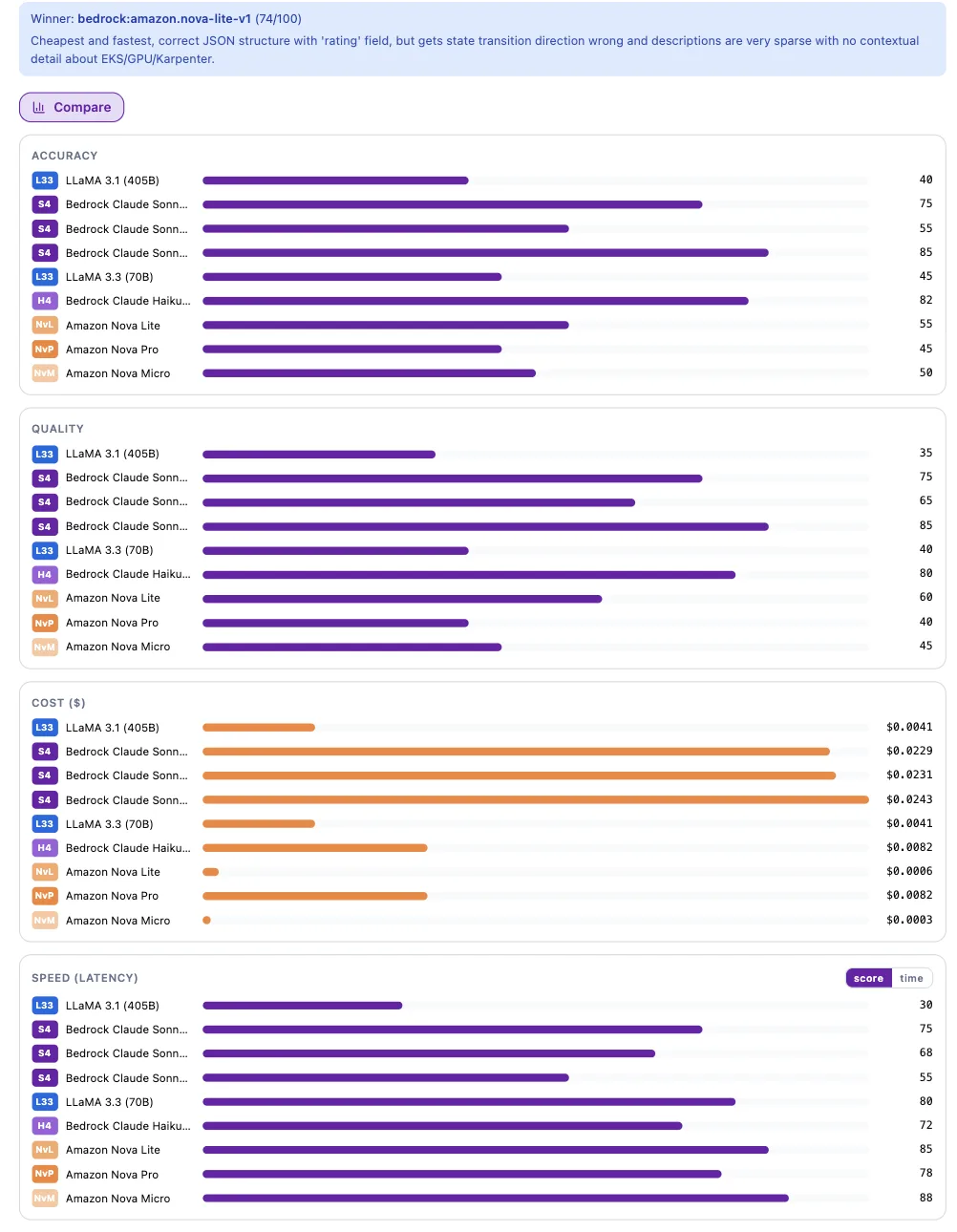
The LLM Showdown
As an AlertD user, you’ve now got a handle on what’s running, what it’s for, and how much it’s costing. The next step is figuring out how to optimize the use case to achieve the same or better outcome at a lower price.
One of AlertD’s most powerful optimizations is the LLM Showdown. The Showdown automatically captures the prompt you’re optimizing and runs it on every available Bedrock model. This is incredibly useful because it isn’t complex advice or modifications to your prompt — it’s simply a parameter switch.
In our case, we were astonished to find that Nova Lite provided middle-of-the-pack accuracy and quality at 1/40th the price of the model we were using. Following this guidance, the infrastructure change tracking feature — which had leapt out to become our highest LLM spend — dropped to below our noise floor.
The takeaway
A single new feature can quietly become your largest line item, and traditional cost coconut won’t tell you why. Deep prompt inspection turns “I’m not really sure” into a ranked, named, dollar-denominated chart — and the LLM Showdown turns that insight into a one-parameter fix. That’s the difference between hoping your token budget is under control and knowing it is.
AlertD is available on AWS Marketplace as AI for cloud operations. Learn more →
FAQs
What is deep prompt inspection?
Deep prompt inspection is a technique that looks inside LLM payloads, meaning the system prompts and user data, to cluster, categorize, and attribute the cost of your AI usage. It is the LLM equivalent of deep packet inspection. Instead of stopping at metadata like source, destination, or inference profile, it analyzes the actual content of each prompt so you can see what you use LLMs for, how much each use case costs, and how those costs rank.
Why doesn't traditional observability work for LLM calls?
Traditional observability captures and enumerates parameter values like dates, numbers, and integers. LLM calls break that model because the parameters are huge blocks of free text that cannot be categorized this way. The meaning of an LLM call lives inside the prompt itself, so you need to inspect the content of the payload, not just its metadata, to understand what is driving cost.
How does AlertD classify LLM prompts without code changes?
AlertD semantically clusters the contents of your prompts and assigns automatically generated, meaningful names to each cluster, such as change-relevance-scoring or resource-diff-analysis. No retooling, instrumentation, or manual tagging is required. The result is a ranked, named breakdown of LLM spend by use case, denominated in dollars.
Does auto classifying prompts use a lot of LLM tokens itself?
No. AlertD classifies prompts using ML methods more typically associated with search engine page deduplication, not by making additional LLM calls. The classification process is very light on LLM usage, so it does not add meaningfully to your token bill.
What is the LLM Showdown?
The LLM Showdown is an AlertD optimization that automatically captures a prompt you want to optimize and runs it against every available Amazon Bedrock model. It compares accuracy, quality, cost, and latency side by side, so switching to a cheaper model becomes a simple parameter change rather than a prompt rewrite or a complex engineering effort.
How much can deep prompt inspection cut LLM inference costs?
In AlertD's own case, the LLM Showdown found that Amazon Bedrock's Nova Lite delivered middle of the pack accuracy and quality at one fortieth the price of the model they were using, a 40x cost reduction. After switching, their Infrastructure Change Tracking feature dropped from their single largest LLM expense to below their cost noise floor. Savings vary by workload, but the method routinely surfaces large, low risk wins.
Does AlertD work with AWS Bedrock?
Yes. AlertD is built for teams running inference through Amazon Bedrock on AWS. It inspects the prompts flowing through Bedrock, attributes cost by use case, and benchmarks your prompts across every available Bedrock model through the LLM Showdown.
How is deep prompt inspection different from Bedrock inference profiles?
Bedrock inference profiles are essentially traditional instrumentation. They tell you which application made a call but rely on naming hygiene and do not reveal what is happening inside the call. Deep prompt inspection peers into the payload itself to determine what the prompts mean and clusters them automatically, giving you insight that inference profiles alone cannot provide.
How do I get started with AlertD?
AlertD is available on the AWS Marketplace as AI for cloud operations, and offers a free 30 day trial. Once connected, it begins classifying your LLM usage and surfacing optimization opportunities like the LLM Showdown without requiring code changes.
